MVCNN enhancement
In the rapidly evolving field of deep learning, even established models can benefit from a fresh look. Recently, our team at TUM—comprising Ronald Ernst, kolusask, and Icheler—took on the challenge of modernizing MVCNN (Multi-View Convolutional Neural Network) as part of our Machine Learning for 3D Geometry course. Our goal was simple yet ambitious: to see how far we could push MVCNN’s performance by integrating state-of-the-art pre-trained networks and revisiting some of its core architectural choices.
Breathing New Life into an Established Model
MVCNN has long been a reliable framework for 3D shape recognition, leveraging multiple 2D views to capture the intricacies of 3D objects. However, much of its architecture was built around older models—like a VGG-16-inspired feature extractor—that, while effective, have since been surpassed by modern deep learning advances.
Upgrading the Feature Extractor
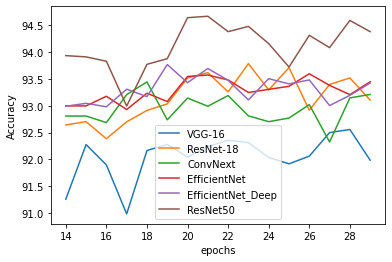
One of our primary modifications was to replace the traditional VGG-16-like feature extractor with newer, pre-trained CNNs. We experimented with architectures like ConvNext and ResNet-18, exploring how these modern networks could enhance MVCNN’s ability to extract robust and discriminative features from 2D projections of 3D models.
A New Dataset: The Unified Collection
In addition to upgrading the network, we also took on the challenge of improving the dataset. We merged two of the most popular datasets in the 3D vision community—ShapeNet and ModelNet—into what we call the Unified dataset. This new dataset aims to provide a richer and more diverse set of examples, pushing the limits of what MVCNN can learn and generalize.
Rethinking Pooling Operations
Beyond network selection, we also revisited a fundamental component of CNNs: the pooling operation. While max-pooling has been the standard in MVCNN, we experimented with mean-pooling and even altered the pooling layers’ positions within the network. These modifications were aimed at understanding how such changes could influence the model’s performance, especially when combined with the new feature extractors.
Training and Performance Insights
Our experiments were carried out in two distinct training stages on ModelNet with shaded images. The results were telling:
- VGG-16: Achieved 95.03% accuracy on ModelNet but only 85.37% on the Unified dataset.
- ConvNext: Slightly improved performance on both datasets, reaching 95.64% on ModelNet and 85.92% on Unified.
- ResNet-18: Offered comparable results to VGG-16 on ModelNet, but with better performance on Unified (85.86%).
- ResNet-18 with Mean-Pooling: Stood out by achieving 87.30% accuracy on the Unified dataset—a testament to the potential of rethinking pooling strategies.
These numbers not only highlight the improvements we achieved but also emphasize the importance of dataset diversity and architectural innovation.
Setting Up and Exploring the Code
For those interested in diving deeper, we have made our code accessible. The environment is fully managed via a Conda setup, ensuring that all dependencies are seamlessly handled. Data preparation scripts are provided to merge and organize the ShapeNet and ModelNet datasets, and the training pipeline is easily configurable through a command-line interface.
Additionally, we integrated support for wandb to track experiments and monitor model performance online, making it easier to iterate and refine future modifications.
Looking Forward
This project has been a rewarding exploration into the impact of modern deep learning components on an established model. By integrating contemporary CNNs and experimenting with fundamental operations like pooling, we have demonstrated that even well-known architectures can be revitalized to meet the demands of today’s challenging 3D recognition tasks.
We believe that these enhancements pave the way for future research, not only in improving MVCNN but also in inspiring similar updates across other legacy models in computer vision. The journey of innovation is continuous, and we’re excited to see where these improvements will lead next.